
안녕하십니까, 간토끼입니다.
지난 포스팅까지는 시계열자료의 추세(Trend)를 이용하여 미래의 시계열을 예측하는 추세분석에 대해서 다뤄봤습니다.
추세를 나타내는 변수 t, 혹은 t의 Polynomial Term을 설명변수로 놓고 시계열자료를 예측하는 일종의 회귀모형을 구축하는 것과 동일한 form이라고 이해하면 됐었죠.
사실 시계열자료를 예측한다는 점에서 앞으로 다룰 모형도 회귀모형을 기반으로 하고 있습니다.
즉 회귀분석을 잘 모르면 시계열분석도 이해가 안 될 가능성이 크니, 회귀모형에 대한 선수 지식이 요구되므로 참고하시기 바랍니다.
그래서 이번 포스팅부터는 최근의 자료에 더 큰 가중값을 주고, 과거로 갈수록 가중값을 지수적으로 감소시킴으로써 미래값을 예측하는 지수평활법(Exponential Smoothing Method)에 대해서 다뤄보겠습니다.
1. 지수평활법(Exponential Smoothing Method)
먼저 지수평활법을 왜 사용하는지부터 짚고 넘어가보죠.
시계열자료의 특징은 자료들의 시간의 흐름에 따라 장기간에 걸쳐 관측된다는 점이겠죠.
즉, '시간'에 따라 관측한다는 점에서 시계열이 생성되는 시스템 자체에 변화가 올 수 있습니다.
예상치 못한 위기, 혹은 자료에 영향을 주는 사건 등이 발생한다는 점에서요.
그러므로 초기에는 잘 맞던 모형이 시간이 경과함에 따라 변화가 발생하여 잘 맞지 않게 되는 경우가 많이 있습니다.
이러한 점에서 오래된 과거와 최근의 자료 모두 동일한 가중치를 두어 미래값을 예측하는 것보다,
오래될수록 낮은 가중치를, 최근의 자료일수록 높은 가중치를 두어 최근의 경향을 잘 반영하는 게 보다 합리적일 수 있죠.
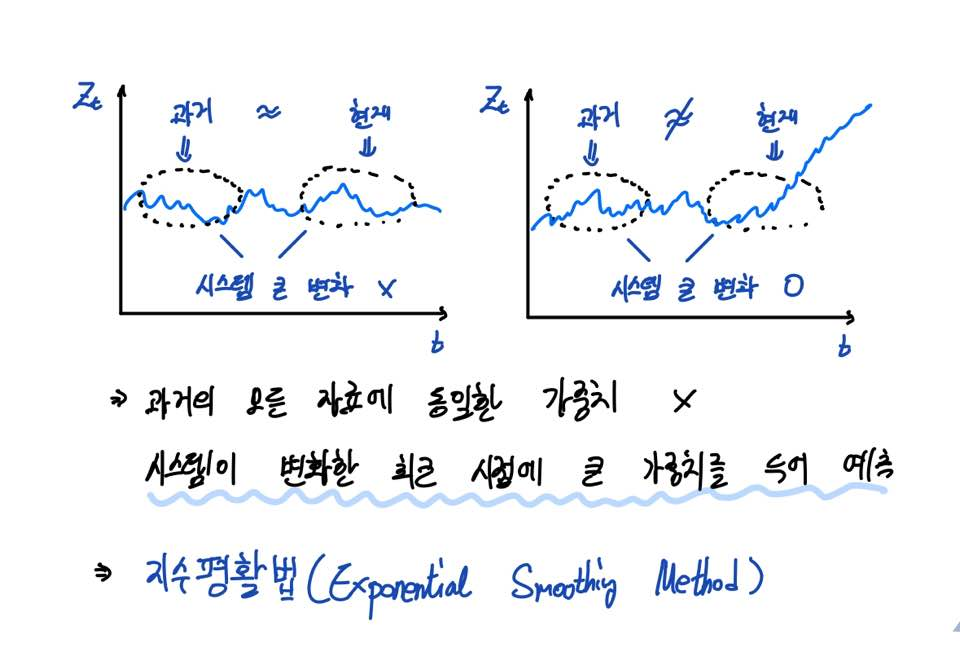
이러한 측면에서 지수평활법은 최근의 자료에 더 큰 가중치를 두고, 과거로 갈수록 지수적으로 가중치를 감소시켜 영향을 적게 반영하는 예측방법을 의미합니다.
2. 단순지수평활법(Simple Exponential Smoothing Method)
단순지수평활법은 지수평활법의 간단한 모형 중 하나입니다.
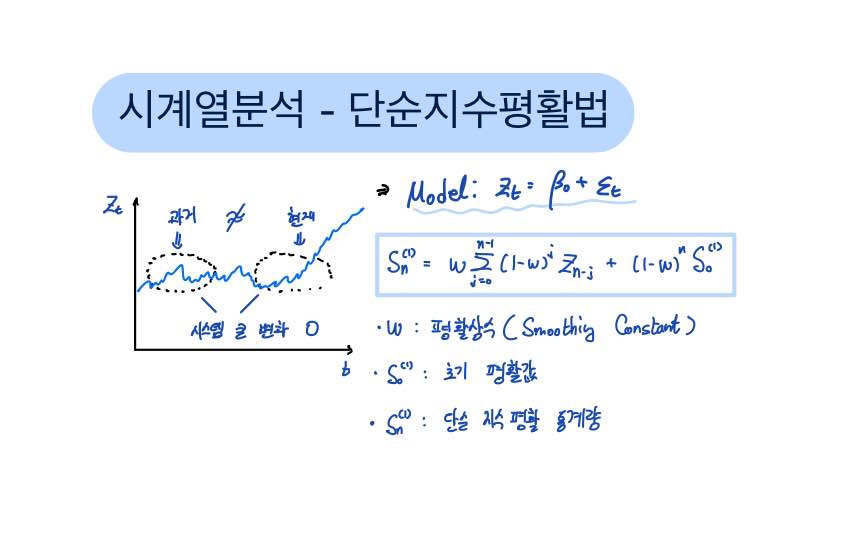
한번 시계열자료가 다음과 같은 모형을 따른다고 생각해보죠.

시계열자료를 구성하는 모형이 Parameter β와 불규칙성분 ε로 이루어진 아주 단순한 모형이죠.
위 모형만 보았을 땐 이전에 다루었던 상수평균모형과 형태가 매우 유사해보입니다.
다만 상수평균모형에서의 Parameter β는 현재 시점까지의 자료 n개를 모두 평균한 단순한 상수였지만,
지수평활법에서의 Parameter β는 Local하게는 비슷한 평균수준이지만, Global하게 보았을 땐 시점별로 상이한 평균수준을 갖는다는 점에서 다릅니다.
즉 새로운 자료가 관측될 때마다 변화의 정보를 수용하여 Parameter β의 추정값이 갱신되는 시스템입니다.
그래서 위와 같은 시스템에서 n-1개의 자료가 생성되었다고 가정해보죠.
그렇다면 현재 시점 n-1로부터 1-시차 후 예측된 MMSE 예측값은 β_(n-1)^이라고 할 수 있습니다.

즉 현재까진 β의 추정량이 관측된 n-1개의 자료들의 평균이라고 한번 생각을 해보죠.

만약 시점 n에서 새로운 관측값이 관측되면 현재까지의 추정량 β^을 갱신해야 합니다.
이때 update를 위한 가중치 parameter w를 이용합니다. (w는 0과 1 사이의 값을 갖습니다.)
즉 시점 n에서의 추정량 β^은 n-1에서의 추정량 β^에 예측오차에 가중치를 곱해준 값을 더해준 꼴로 표현이 됩니다.
다시 말해서 시점 n에서의 추정량 β^은 시점 n-1에서 시계열자료 Z를 예측할 때 발생한 예측오차의 부분만큼 수정된다는 것입니다.

이제 시점 n에서의 추정량 β^을 S_(n) 이라고 해보죠.
그렇다면 S_(n) 기호를 이용하여 위와 같이 식을 쓸 수 있습니다.
좀 더 Recursive하게 전개해볼까요?
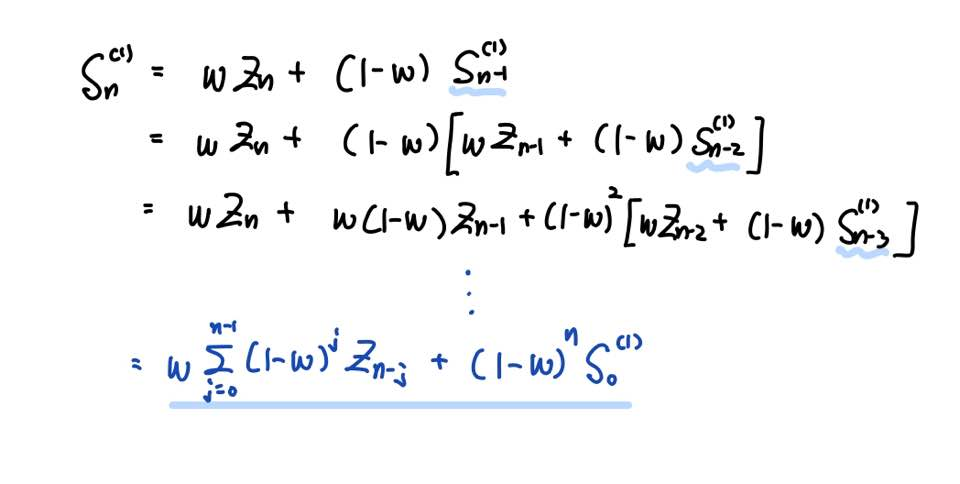
반복적으로 써내려가다보면 다음과 같이 식을 정리할 수 있습니다.

정리하면 가중치 w는 평활상수(Smoothing Constant)라고 부르며, S_(0)은 초기 평활값, 그리고 시점 n에서의 S는 단순지수평활 통계량이라고 부릅니다.
이 단순지수평활 통계량을 이용해 다음 시차의 자료를 예측하는 것이죠.
좀 더 정리해보겠습니다.

n이 점근적으로 커짐에 따라 위 성분들은 다음과 같이 수렴합니다.우선은 (2)번째 성분이 0에 수렴한다는 것만 기억해두도록 하죠.

이러한 점근적 성질을 이용하면 단순지수평활 통계량이 시점 n까지의 자료들의 가중평균(Weighted Average)로 정리됨을 알 수 있습니다.

또한 이 가중값의 구조를 살펴보면 최근의 자료일수록 가중치가 크고, 과거의 값일수록 가중치가 점점 작아짐을 알 수 있습니다.
왜냐하면 w와 1-w 모두 0과 1 사이의 값이므로, 곱해질수록 값이 점점 0에 가까워지기 때문이죠.
그리고 이러한 가중치가 '지수적으로' 작아지므로, 이러한 의미에서 S(1)을 지수평활 통계량이라고 부릅니다.
이러한 단순지수평활 통계량은 Parameter β의 비편향추정량임을 보일 수 있습니다.
단순지수평활 통계량에 기댓값을 취해주면 n이 커짐에 따라 β가 됨을 다음과 같이 확인할 수 있습니다.

그러므로 시점 n에서의 β의 추정량으로 단순지수평활 통계량이 쓰일 수 있으며,
시점 n에서 l-시차 후 예측값으로도 단순지수평활 통계량이 쓰일 수 있습니다.
이를 단순지수평활법에 의해 구한 예측값이라고 합니다.
이러한 단순지수평활법의 장점은 예측값의 갱신이 쉽다는 것입니다.
- 새로운 자료가 관측될 때마다 처음부터 모든 자료를 이용하여 예측값을 구할 필요없이 최근의 관측값과 바로 직전 시점에 구한 예측값 S_(n-1) 만 있으면 됩니다.
- 왜냐하면 바로 직전 시점에 구한 예측값 S_(n-1)에 과거의 정보들이 모두 들어있으므로, S_(n-1)와 최근 자료만의 선형결합에 의해 예측값 S_(n)을 구할 수 있다는 것이죠.
n이 크다고 하면 위에서 보인 점근적 성질에 의해 초기 평활값(상수항) 성분이 필요가 없겠으나, 그렇지 않다면 불가피하게 초기 평활값을 이용하여 단순지수평활 통계량을 구해야 합니다.

이때 초기 평활값을 선택하는 방법은 통상적으로 위 절차를 따른다고 합니다.
만약 시계열의 수준 변화가 대체로 크다면 초기 평활값으로 첫 시점의 관측값을 선택하고,
그렇지 않다면 자료들의 표본평균을 사용합니다.
또한 평활상수 w에 대한 설정도 필요하겠죠.
사실 초기 평활값은 n이 클 경우 급속히 작아지므로 큰 역할을 하진 않지만, 그에 비해 평활상수에 대한 선택은 매우 중요합니다.
만약 평활상수의 값이 작으면 평활의 효과가 커서 예측값은 시계열의 지엽적인 변화에 둔감하게 반응할 것입니다.
혹은 값이 크다면 평활의 효과가 작아 최근의 관측값에 의해 크게 영향을 받겠죠. 그러므로 지엽적인 변화에 민감한 반응을 보일 것입니다.

평활상수를 선택하는 방법으로 위와 같은 방법을 생각해보죠.
t시점의 자료에 t-1시점에서의 예측값을 빼준 예측오차를 가정하면,
이 예측오차의 SSE를 Cost Function으로 간주할 수 있겠습니다.
그렇다면 이 Cost Function을 최소화하는 상수 w를 선택한다면 '예측'의 관점에서 보았을 때 바람직하겠죠.
왜냐하면 예측오차를 최소화한다는 것은 결국 예측력을 높여준다는 것이니깐요.
또 다른 관점으로는 Brown이란 학자는 평활상수를 0.05와 0.3 사이의 값으로 선택하는 것을 제안하였다고 하는데요.
이처럼 평활상수 w의 선택이 임의적일 수 있다는 것이 지수평활법의 단점이라고 할 수 있습니다.
또한 이론적으로 완벽하진 않아 추후 다룰 ARIMA 모형보다 신뢰도가 떨어집니다.
비교적 간단한 예측법이니깐요.
하지만 그렇기에 직관적이고 사용하기 쉬워 일반인들이 사용하기 좋다는 것은 장점일 수 있겠죠.
다음 포스팅은 단순지수평활법의 단순함을 보완한 이중지수평활법에 대해서 다뤄보겠습니다.
감사합니다.
잘 읽으셨다면 게시글 하단에 ♡(좋아요) 눌러주시면 감사하겠습니다 :)
(구독이면 더욱 좋습니다 ^_^)
- 간토끼(DataLabbit)
- 학부 4학년(a fourth-grade undergraduate)
- University of Seoul
- Economics, Data Science
'Statistics > Time Series Analysis' 카테고리의 다른 글
| [시계열분석] 추세모형에 의한 분해법 (2) | 2020.12.23 |
|---|---|
| [시계열분석] 이중지수평활법(Double Exponential Smoothing Method) (0) | 2020.11.17 |
| [시계열분석] 자기회귀오차모형(Autoregressive Error Model) (2) | 2020.11.12 |
| [시계열분석] Durbin-Watson(DW) Test (4) | 2020.11.11 |
| [시계열분석] 다항추세모형(2) - 선형추세모형(Linear Trend Model) (5) | 2020.11.06 |