
안녕하십니까, 간토끼입니다.
이번 포스팅은 회귀분석을 위한 가설검정의 기초 개념을 소개하겠습니다.
사실 회귀분석을 접하기 위해서는 기초통계학이 당연히 전제가 되어야 하는데요.
다만 기초통계학을 배운지 제법 시간이 흐른 분들이 계실 수도 있고 ...
경제학과 학생들을 예로 들면, 경제통계학을 배우고 오랜만에 계량경제학을 듣는 분들은 이 기초통계 내용을 다 까먹어서 힘들어 하더라고요. (저도 경제학부 출신이다보니 ... 간혹 지인들에게 개념을 설명해주다보면 많이 까먹은(?) 케이스를 많이 봤습니다. 허허 )
그런 맥락에서 리마인드 정도로 가볍게 다루는 포스팅입니다. 수리적인 부분을 정말 제외하고요 !!
*수리적인 부분을 기대하신 분들에겐 추후 수리통계학을 다루면서 .... 소개하겠습니다.

먼저 가설검정의 개념을 차근차근 생각해보죠.

우선 회귀분석은 설명변수 x와 반응변수 y 간의 관계를 찾는 분석기법입니다.
설명변수 x가 1개인 단순선형회귀모형을 가정하면, 위와 같이 f(x) = b0 + b1x 꼴로 선형회귀식을 추정할 수 있겠죠.
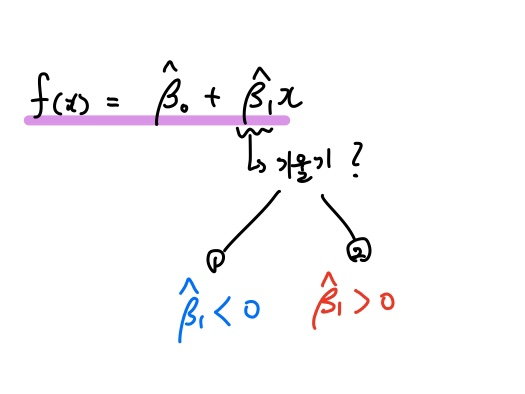
이때 1차함수 정의에 의해 직선의 기울기는 기울기계수 b1의 부호에 따라 달라지게 됩니다.
만약 양(+)의 계수라면 우상향할 것이고, 음(-)의 계수라면 우하향하겠죠.

만약 설명변수 x를 소득, 그리고 반응변수 y를 식료품 지출액인 경제학적 모형을 가정하면,
소득이 증가할수록 식료품 지출액이 증가할지, 감소할지를 판단하는 것은 중요한 문제입니다.
만약 비례하는 관계라면 이 식료품은 정상재일 것이고, 감소한다면 이 식료품은 열등재가 되겠죠.
이때 우리는 이 기울기계수 b1이 "실제로는" 어떤 부호를 갖게 되는지 판단해야 합니다.
즉 단순히 표본통계량이 아닌 모수(Parameter)가 어떤 부호를 갖는지 추정해야 하죠.
이를 위해 우리가 세운 가설(Ex. +/- 부호 결정)을 검정하는 것을 가설검정이라고 합니다.

가설검정의 요소는 위와 같습니다.
하나씩 살펴보도록 하죠.
1. 귀무가설

귀무가설이란 가설이 기각되기 전까지 우리가 고수하는 믿음을 의미합니다.
즉 모집단의 특성(모수)에 대해 옳다고 제안하는 잠정적인 주장을 의미합니다.
만약 대한민국 성인 남성의 평균 키가 165cm이다. 라고 주장이 존재한다면 이는 귀무가설이 됩니다.
기호로는 H0 라고 합니다. 영가설이라고도 부릅니다만... 저는 귀무가설이라는 말을 더 좋아합니다.
2. 대립가설

대립가설이란 우리가 알고자 새롭게 주장하는 가설입니다.
위 귀무가설 예시를 이어서 예로 들면, 대한민국 성인 남성의 평균 키는 165cm가 아니다, 혹은 165cm보다 크다(작다) 라는 주장을 한다면, 이는 대립가설이 됩니다.
그렇기에 우리는 무엇이 맞는 가설인지 판단해야겠죠.
3. 검정통계량

검정통계량이란 가설검정에 사용된 표본(Sample) 데이터로부터 계산된 랜덤 변수를 의미합니다.
대한민국 성인 남성의 평균 키를 구하기 위해 가장 좋은 건 모든 성인 남성의 키를 구하는 것이겠지만,
이는 현실적으로 불가하다는 것을 이전 기초통계학 포스팅에서 설명하였습니다.
그래서 우리는 표본을 추출하여 표본통계량을 구하는 것이었고요.
이때 이 표본으로부터 가설을 검정하기 위해 구한 통계량을 검정통계량이라고 합니다.
다만 검정을 위해 다양한 분석기법을 사용할 수 있는데요. 그에 따라 검정통계량이 따르는 확률분포는 달라지게 됩니다.
대표적으로는 대부분이 아실 Z-검정, 그리고 회귀분석 간에 사용하는 T-검정이 있겠고요.
만약 Z-검정을 한다면 검정통계량은 표준정규분포를, 그리고 T-검정을 한다면 t-분포를 따르게 됩니다.
아무튼 간에 이 검정통계량을 이용해 귀무가설의 기각 여부를 판별하게 됩니다.
4. 기각역

기각역은 귀무가설의 기각으로 이어지는 검정통계량의 범위를 말합니다.
이 기각역은 가설검정 전에 세우는 '유의수준(Level of Significance)'에 따라 크기가 달라지는데요.
만약 검정통계량이 이 기각역에 들어간다면 우리는 귀무가설을 기각할 수 있습니다.
단, '유의수준'에 따라 기각역의 크기가 달라진다고 했으므로,
만약 기각역에 검정통계량이 들어간다면, 우리는 "이 특정한 유의수준 하에서 귀무가설을 기각할 수 있다." 라고 결론을 내릴 수 있게 됩니다.
자 그렇다면 여기서 궁금한 점!

요 유의수준과 유의확률이라는 개념은 무슨 의미를 가질까요?
궁금하시죠?
다음 포스팅에서 알기 쉽게 다뤄보겠습니다.
감사합니다.
잘 읽으셨다면 게시글 하단에 ♡(좋아요) 눌러주시면 감사하겠습니다 :)
(구독이면 더욱 좋습니다 ^_^)
- 간토끼(DataLabbit)
- University of Seoul
- Economics & Data Science
'Statistics > Regression Analysis' 카테고리의 다른 글
| [회귀분석] 회귀계수의 유의성 검정 (8) | 2022.04.30 |
|---|---|
| [회귀분석] 유의수준과 유의확률 (4) | 2022.03.03 |
| [회귀분석] 원점을 지나는 회귀모형(Regression Through The Origin) (8) | 2020.10.21 |
| [회귀분석] 최소제곱추정량 β0의 기댓값, 분산 유도 (12) | 2020.10.20 |
| [회귀분석] 가우스-마르코프 정리(Gauss-Markov Theorem) 증명 (16) | 2020.10.14 |