[회귀분석] 결정계수(R²; Coefficient of Determination)
Review
참고 포스팅 :
2020/09/27 - [Statistics/Regression Analysis] - [회귀분석] ANOVA(분산분석)를 이용한 회귀분석 접근 (1) - 제곱합(Sum of Squares)
2020/09/29 - [Statistics/Regression Analysis] - [회귀분석] ANOVA(분산분석)를 이용한 회귀분석 접근 (2) - F ratio 유도
2020/10/03 - [Statistics/Regression Analysis] - [회귀분석] ANOVA(분산분석)를 이용한 회귀분석 접근 (3) - ANOVA Table 해석
안녕하십니까, 간토끼입니다.
지난 포스팅까지 총 3부작으로 ANOVA를 이용해 회귀분석을 다루어보았습니다. (사실 ANOVA는 회귀분석의 특별한 형태라고 합니다.)
특히 직전 포스팅에서 F-ratio를 다루면서 모형의 적합도를 평가해보았죠.
이번 포스팅에서는 모형의 적합도를 평가하는 다른 평가 지표인 결정계수(Coefficient of Determination)에 대해서 다뤄보겠습니다.
지난 포스팅으로 잠깐 돌아가보죠.
우리는 회귀모형을 다음과 같이 변동의 합으로 분해했었습니다.

궁극적으로는 SSR이 커진다는 것은 SSE가 작아진다는 것이고, SSE가 작아지면 설명 불가능한 변동이 작아지는 거니까,
우리가 추정한 모형을 바탕으로 반응변수 Y를 보다 잘 예측할 수 있게 된다는 것이라고 했었습니다.
그쵸?
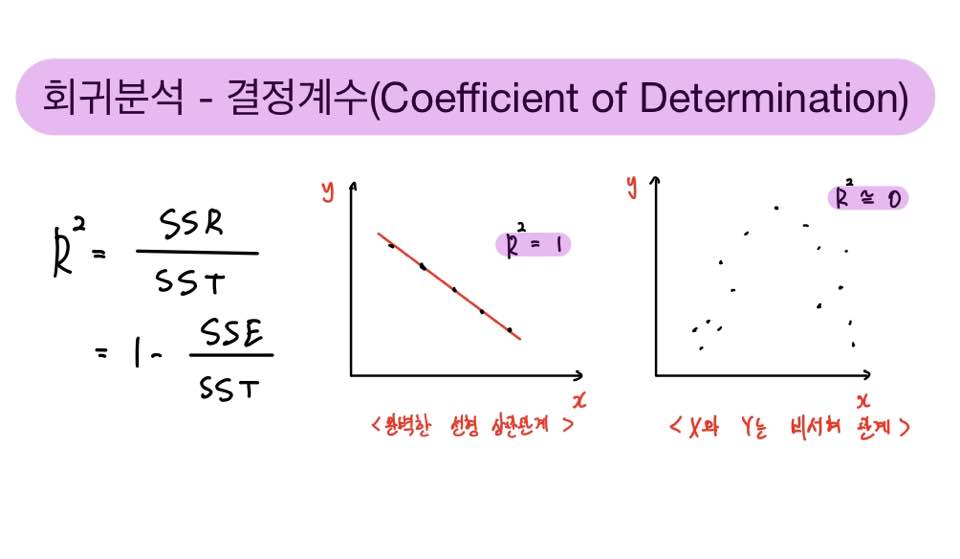
이를 바탕으로 정의되는 결정계수(R²,R Square) 는 회귀모형 내에서 설명변수 x로 설명할 수 있는 반응변수 y의 변동 비율입니다.
즉 총변동(SST)에서 설명 가능한 변동인 SSR이 차지하는 꼴(SSR / SST)로 나타낼 수 있습니다.

SST는 SSR과 SSE의 합으로 표현되니까, SSR = SST - SSE 로도 쓸 수 있겠죠?
이를 가운데 식에 대입해보면 우측의 식이 나옵니다.
결정계수를 좀 더 직관적으로 표현해보죠.

뭐랄까 직관적으로 이런 느낌입니다.
주황색으로 칠한 부분을 Y의 총변동이라고 했을 때, 우리가 만든 회귀모형을 보라색이라고 하면,
보라색이 커질수록 우리의 모형이 Y를 잘 설명한다고 볼 수 있겠죠?

그래서 R²는 0부터 1사이의 값을 갖습니다.
0에 가까울수록 설명변수 X와 반응변수 Y는 선형 상관관계의 정도가 없다고 하고,
1에 가까울수록 선형 상관관계의 정도가 크다고 할 수 있습니다.
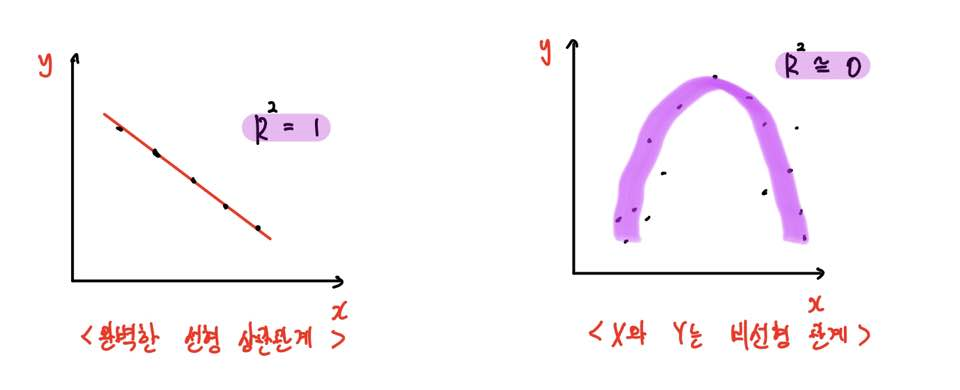
만약 R²가 1이라면 좌측의 그래프와 같이 완벽한 선형 상관관계가 나타남을 알 수 있습니다.
SSR = SST라면 R² = 1이니까, SSE = 0이라는 얘기죠. (SSE = 0 이라는 얘기는 오차가 아예 없다는 것과 같겠죠?)
그러나 R²이 거의 0에 가깝다고 하더라도 X와 Y의 관계가 전혀 없는 것은 절대 아닙니다.
만약 우측의 그래프와 같이 X와 Y가 비선형의 관계라면, 이를 고려하지 않은 회귀모형은 이 비선형성을 잡아낼 수 없습니다.
이런 경우, 설명변수 X에 Polynomial Form(Ex. x² 형태)를 취해 넣어주게 되면, R²은 1에 가깝게 될 것입니다.
그리고 선형회귀분석은 인과성이 아닌 상관성에 기반하고 있는 통계 분석 기법입니다.
이러한 상관성은 우리가 이전에 다루었던 공분산과 상관계수 의 상관계수로부터 유도될 수 있는데요.
재밌게도 단순선형회귀모형에서 R²와 상관계수 사이에는 제곱의 관계가 성립합니다.
즉 표본상관계수의 제곱 r² = R² 가 됩니다.
한번 증명해보죠.
# R² is the square of the sample correlation coefficient r

( 중간에 SSR이 왜 저렇게 되는지 모르겠는 분은 => 여기 를 참고해주세요.)
간단하죠?
다만 끝부분에 (a)가 왜 상관계수가 되는지 혹시나 모르실 분들을 위해 설명을 준비했습니다.

쉽죠?
회귀분석을 하다 보면 R² 이 높게 나올 때도 있고, 낮게 나올 때도 있습니다.
그럼 R² 이 클수록 우리가 세운 모델은 중요한 모델일까요?
답은 그렇지 않습니다.
다시 생각해보면 R²은 SSR이 모형 전체에서 차지하는 비중이 클수록 커질 것입니다.
만약 이게 과학에서의 실험 등과 같이 반응변수 Y를 설명할 수 있는 X가 어떤 게 있는지 명확하고, 이러한 X들을 통제할 수 있다고 하면 SSR은 당연히 크게 나올 것입니다.
하지만 사회과학에서의 연구는 그렇지 못한 경우가 많습니다.
예를 들어 반응변수 Y가 소득이라고 가정하면, 소득을 설명하는 변수는 너무나 많습니다.
나이가 10대, 60대 이상에 비해 30, 40대일 때 소득이 더 높다는 점에서 나이도 중요한 변수일 수 있고,
물가가 높을수록 소득이 높아질 수도 있고, 근로 시간이나 학력 수준 등 소득에 영향을 미치는 변수는 너무나 많습니다.
즉 사회과학에서의 연구는 모든 변수를 완전히 통제할 수 없다는 점에서 완벽한 연구는 불가능합니다.
우리가 알지 못하는 미지의 외부 요인들도 많을 것이고요.
그렇기에 만약 소득을 예측하는 회귀모형을 구성할 때 이러한 설명변수를 모두 포함하지 못한 채 분석을 한다면,
변수들 간의 관계는 통계적으로 유의하게 도출될 수 있으나, 정작 R² 값은 생각보다 낮을 수 있습니다. (0.1 ~ 0.3)
또한 시간이 지날수록 과거에 비해 상승하는 Trend를 가진 물가, GDP 등의 거시경제지표의 경우,
별 다른 노력을 하지 않고 '시계열자료'를 썼다는 이유만으로 회귀모형의 R² 값은 0.99 이렇게 나올 수도 있습니다.
만약 예측을 중요시하는 머신러닝이라면 일반적으로 반응변수가 연속형 변수일 때 모형의 성능을 평가하는 지표로 R²를 사용합니다.
그러나 해석을 중요시하는 사회과학 등의 경우, Y를 얼마나 잘 예측하는지에만 기초하여 모형을 평가해서는 안 됩니다.
예를 들면 회귀계수의 부호(Sign) 및 크기, 통계적 유의성 및 해석적인 관점에서의 유의미함, 추정의 정확성, 모형에 포함되지 않은 외부 요인 등을 고려해서 R²를 적절히 사용해야 합니다.
극단적인 예로 초콜릿 소비량과 머리카락의 길이가 매우 높은 양의 상관관계(r = 0.95)가 있다고 가정하면,
초콜릿 소비량(y) = b0 + b1 * 머리카락의 길이(x)
라는 모형의 R²은 거의 1에 가깝겠죠.
사실 논리적으로 머리카락이 길수록 초콜릿을 많이 먹는다는 건 말이 안 되므로, 두 변수의 상관성이 타당하다고 볼 수 없는 '우연적인 상관성'에 기반한 결과기 때문에, 위 모형은 쓸모가 없습니다.
그러므로 R² 가 높다고 모형의 결과를 마냥 맹신하면 안 됩니다.
그렇다고 R² 가 0이 돼도 상관없다는 의미는 아닙니다.(R² 가 0이 되면 아마 F-ratio가 유의하지 못할 겁니다.)
최소한 설명변수 x와 반응변수 y 간의 관계를 보이려면 어느정도의 상관성은 당연히 있어야겠죠.
즉 크면야 좋기는 하겠지만, 모형을 평가하는 절대적인 기준으로써 R²가 사용되어서는 안 된다는 것이죠.
정리하면 R²는 회귀모형의 Goodness of Fit(적합도)으로 사용될 수 있으나 모형을 평가하는 데 절대적인 기준이 되지 않으며,
예측을 중요시하는 머신러닝의 회귀 문제에서는 R²이 모델의 성능을 나타내는 중요한 기준이 될 수 있습니다.
그러나 변수 간의 관계를 설명하는 해석적인 관점의 회귀분석에서는 절대적인 기준이 되지 않습니다.
또한 R²은 다음과 같은 관계가 성립합니다.

다음 포스팅에서는 최소제곱추정량을 선형 추정량(Linear Estimator)로 표현하는 방법에 대해 다뤄보도록 하겠습니다.
감사합니다.
잘 읽으셨다면 게시글 하단에 ♡(좋아요) 눌러주시면 감사하겠습니다 :)
(구독이면 더욱 좋습니다 ^_^)
- 간토끼(DataLabbit)
- University of Seoul
- Economics, Data Science