
Review
참고 포스팅 :
2020/09/27 - [Statistics/Regression Analysis] - [회귀분석] ANOVA(분산분석)를 이용한 회귀분석 접근 (1)
[회귀분석] ANOVA(분산분석)를 이용한 회귀분석 접근 (1)
Review 참고 포스팅 : 2020/09/17 - [Statistics/Regression Analysis] - [회귀분석] 단순선형회귀분석(Simple Linear Regression) 개념 [회귀분석] 단순선형회귀분석(Simple Linear Regression) 개념 Review 참고..
datalabbit.tistory.com
안녕하십니까, 간토끼입니다.
지난 포스팅에 이어서 ANOVA를 이용해 회귀분석에 좀 더 적용해보도록 하겠습니다.
앞으로 할 포스팅은 크게 (1) F-통계량으로의 유도 과정, (2) ANOVA TABLE를 해석하여 모형 적합도 평가 이렇게 두 파트로 나눌 수 있는데요.
통계에 대한 개념이 약하신 분들은 이번 포스팅은 생략하고 (2)로 넘어가셔도 무방합니다.
핵심은 파트(2)에 있는데, 그래도 열심히 썼으니 보셔도 좋습니다 ㅎㅎ
*분량 조절 실패로 파트(2)는 다음 포스팅에서 다룹니다.

1. SSE/σ² ~ χ²(n-2) 유도

먼저 오차가 기댓값이 0이고 분산이 σ²인 정규분포를 따른다는 오차의 정규성 가정 하에
표준화 공식을 이용해 Z라는 확률변수를 위와 같이 정의하겠습니다.
이때 당연히 Z는 표준정규분포 N(0,1)을 따를 것이고요.
오차의 기댓값이 0이므로, Z = e/σ 라고 할 수 있으며, 다시 쓰면 e/σ ~ N(0, 1)라고 쓸 수 있습니다.
그렇죠?

이때 e/σ를 제곱하면 이는 자유도가 1인 카이제곱분포를 따릅니다.
바로 카이제곱분포의 정의때문인데요.
확률변수 Z₁, … , Z_k 가 각각 표준정규분포 N(0, 1)을 따르고, 서로 독립일 때,
(Z₁)² + … + (Z_k)²
의 분포를 자유도 k인 카이제곱분포라 합니다.
이 때, 기호로서 (Z₁)² + … + (Z_k)² ~ χ²(k) 로 나타낼 수 있습니다.
그러므로 표준정규분포를 따르는 확률변수 e/σ의 제곱은 자유도가 1인 카이제곱분포를 따르는 것이죠.
이번 포스팅에서 카이제곱분포에 대한 얘기가 자주 등장하니 잘 기억해두시기 바랍니다.

자 그렇다면 위 정의에 의거하여,
확률변수 (e/σ)²를 각각 n개 더한 값은 자유도가 n인 카이제곱분포를 따를 것입니다.
(이때 오차항은 서로 독립이라는 가정이 존재하므로, 카이제곱분포의 유도가 가능합니다.)
그리고 자유도가 n인 카이제곱분포를 따르는 확률변수의 기댓값은 자유도 n과 같습니다.
따라서 확률변수 (e/σ)²를 각각 n개 더한 값의 기댓값은 위와 같이 분포의 자유도인 n이 됩니다.
* E[SSE/σ²] = n
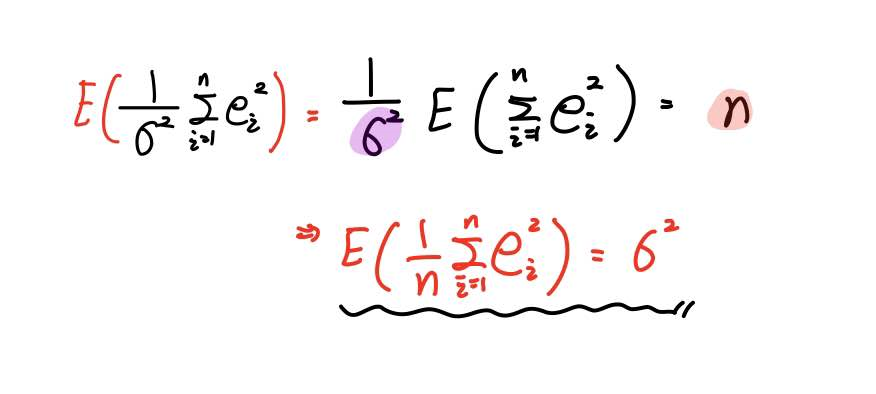
이때 σ² 은 상수니까 기댓값 밖으로 나올 수 있죠?
위와 같이 σ²과 n의 위치를 서로 바꿔주면 SSE를 n으로 나눠준 값의 기댓값이 σ²이 되는 것을 알 수 있습니다.

하지만 오차는 True model(모집단으로부터 얻어낸 회귀모형)에서의 편차를 말하죠?
즉 관측 불가능한 값입니다.
따라서 우리는 관측 불가능한 오차 대신, 오차를 추정할 수 있는 잔차를 대신 사용해야 합니다.
이때 잔차에서 fitted value인 y_hat에 제약 조건이 2개 있었죠?
(모르시는 분들은 이전 포스팅을 보고와주세요.)
따라서 오차 대신 잔차를 사용할 경우, 자유도는 관측치 n개에서 2를 뺀 값인 n-2가 됩니다.
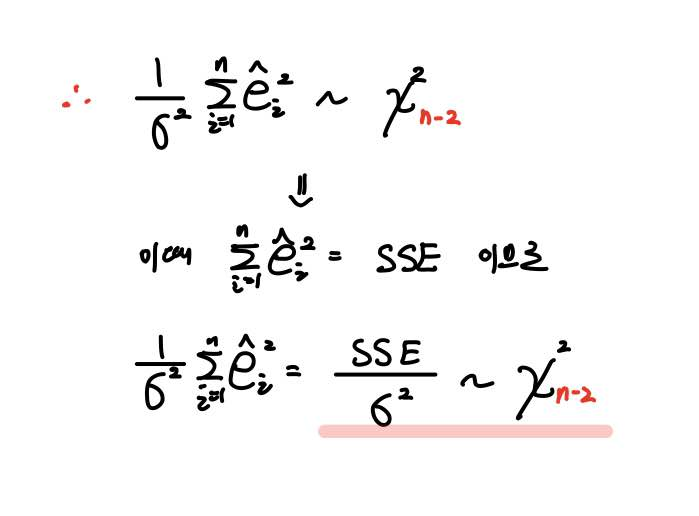
그러므로 위와 같이 자유도가 n인 카이제곱분포가 아니라,
자유도가 n-2인 카이제곱분포를 따르는 것을 알 수 있습니다.
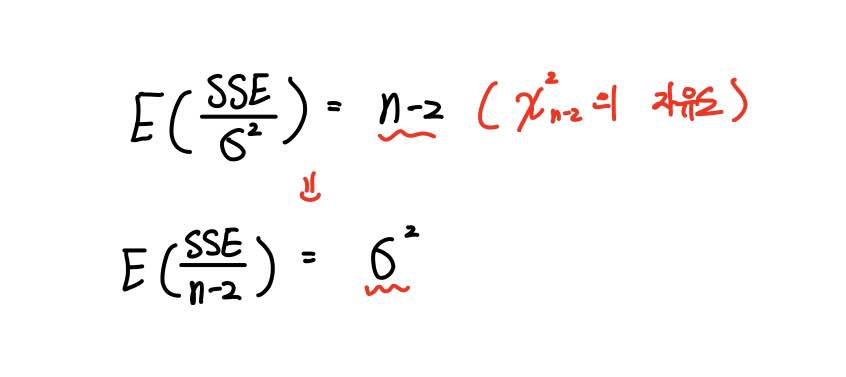
마찬가지로 카이제곱분포를 따르는 확률변수의 기댓값은 카이제곱분포의 자유도라는 성질을 적용해주면,
위 확률변수(SSE/σ²)의 기댓값은 분포의 자유도인 n-2가 되며,
앞에서 했던 것처럼 σ²와 n-2의 위치를 바꿔줄 수 있겠죠?

여기서 중요한 개념을 하나 소개하고 넘어가자면,
평균제곱오차(Mean Square Error; MSE)는 오차항(Error term)의 모분산의 추정량을 나타냅니다.
(# 여기서 모분산은 y의 분산이 아닌 오차항의 분산입니다.)
이는 잔차제곱합(SSE)를 자유도 n-2로 나눠준 값으로 나타낼 수 있는데요.
n이 아닌 n-2로 나눠주는 이유는 위에서 언급했다시피 SSE 식에서 제약조건이 2개(parameter의 개수: β0, β1)이 존재하기 때문에 n-2로 나눠주는 것입니다.
그렇기에 이 모분산의 추정량, 즉 MSE의 기댓값은 우측에서 볼 수 있는 것처럼 오차항의 모분산이 되며,
추정량의 기댓값이 모수와 같으므로, 불편추정량이라고 할 수 있습니다.
2. SSR/σ² ~ χ²(1) 유도
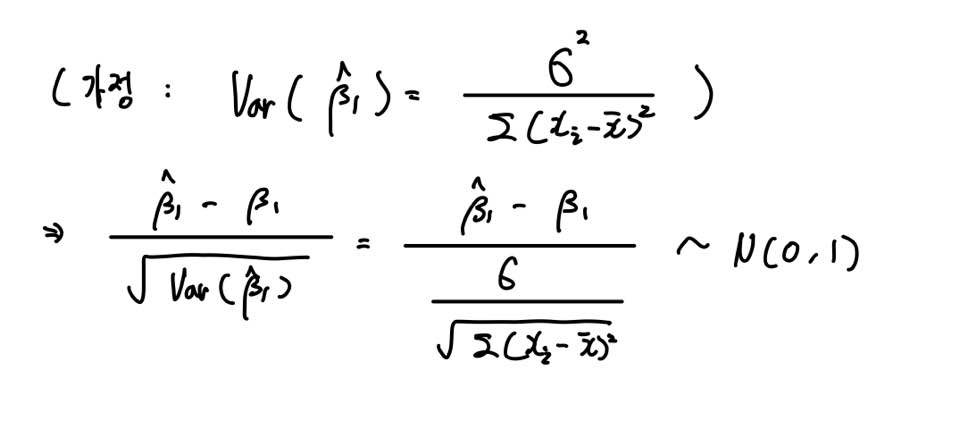
먼저 β1의 Estimator의 분산이 위와 같다고 가정하겠습니다.
(유도과정은 ANOVA 시리즈가 끝나면 바로 다루겠습니다.)
앞서 다루지는 않았지만 오차항의 정규성 가정을 할 경우, 반응변수 y 역시 정규분포를 따르게 되며,
β1의 Estimator가 y를 포함하는 선형 추정량이라는 점에서 최소제곱추정량은 정규분포를 따릅니다.
(최소제곱추정량이 선형 추정량이라는 것 또한 바로 다루겠습니다. 이후 포스팅을 기대해주세요^^)
자 그래서 위와 같이 β1의 Estimator에 대해 표준화를 해주면 기댓값이 0이고 분산이 1인 표준정규분포 N(0,1)를 따르게 됩니다.
앞서 다루었던 과정과 비슷하죠? 바로 카이제곱분포로 유도하기 위한 작업입니다.
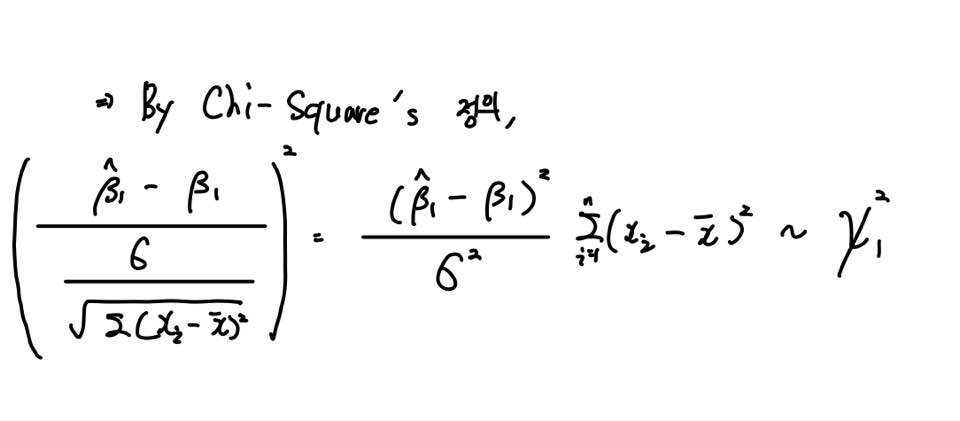
이때 포인트는 자유도가 1인 카이제곱분포를 따른다는 건데요.
왜냐하면 앞선 (1)의 경우는 확률변수를 제곱한 값을 n개 더해서 자유도가 n인 카이제곱분포를 따르게 유도했으나
(물론 오차를 잔차로 바꾸면서 자유도는 n-2가 됐죠)
(2)의 경우는 (1)과 다르게, 확률변수를 제곱한 값을 여러개 더하지 않았잖아요?
그래서 자유도는 1이 됩니다.
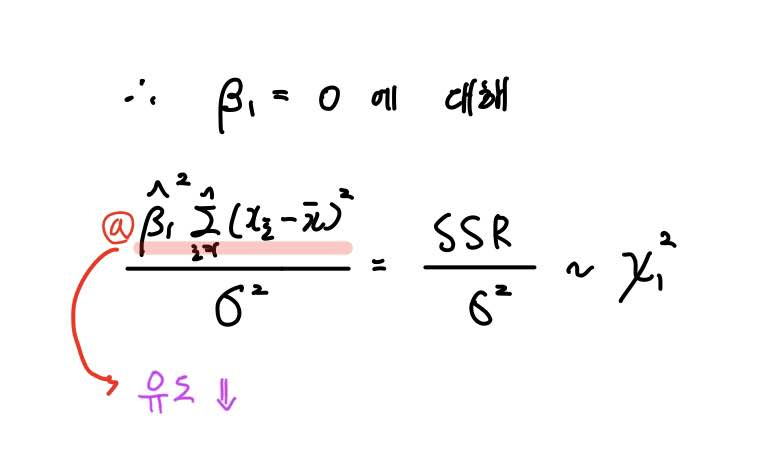
이때 β1 = 0 이라는 가정을 하면, 식은 위와 같이 바뀌게 됩니다.
특히 β1 = 0 이라는 가정을 하는 이유는 모형의 적합도 검정을 위함인데요.
쉽게 말해서 우리는 지금 β1이 0인지 아닌지를 파악하는 작업을 하는 중입니다.
이러한 파악을 위해 우선 β1 = 0 이라는 가정을 한다고 알아두시면 될 것 같습니다.
각설하고 (a)식이 왜 SSR이 되는지 어려워하실 분들이 계실 것 같습니다.
유도 과정을 한번 보시죠.
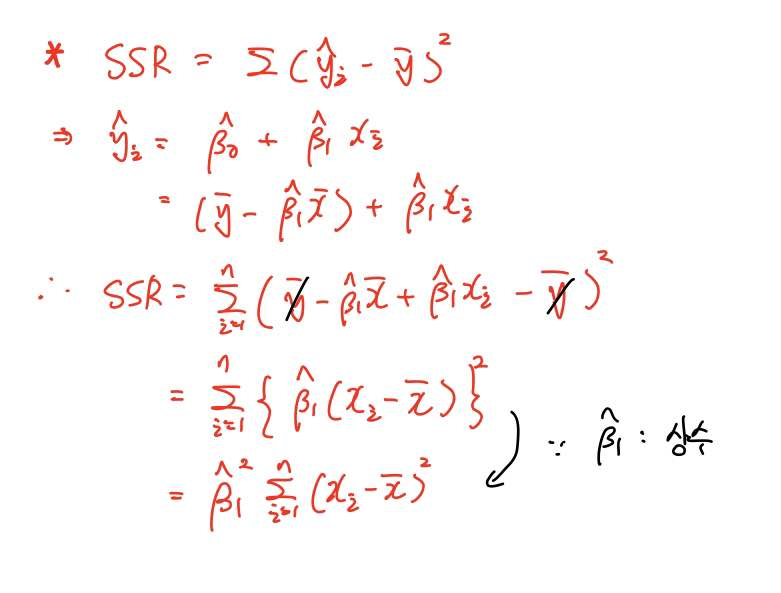
SSR을 약간 변형해주면 (a)식과 형태가 똑같아집니다.
이해가 되시죠?

자 그래서 우리는 위와 같은 과정을 통해 3가지의 사실(Fact)를 얻어낼 수 있었습니다.
3번째 fact는 그냥 SSR과 SSE가 서로 독립이라는 사실만 짚고 넘어가겠습니다.
이러한 Fact들을 바탕으로 우리는 다음과 같이 F-ratio를 정의할 수 있습니다.
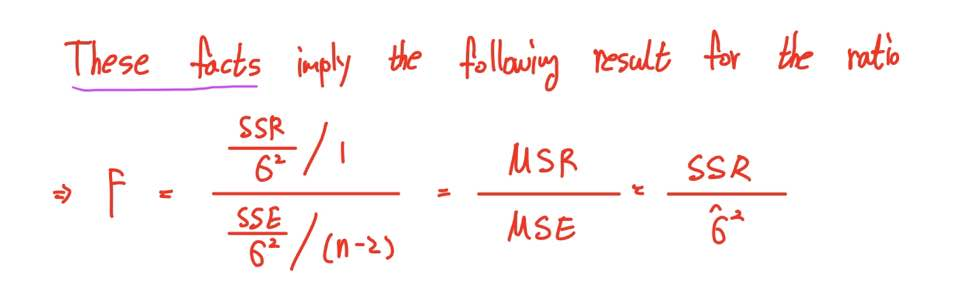
F-ratio, 다른 말로 F-통계량은 MSR을 MSE로 나눈 값으로 정의됩니다.
이게 어떻게 된 걸까요?

바로 F-분포의 성질때문입니다.
F-분포는 카이제곱분포를 따르는 서로 독립인 확률변수 간의 결합으로 나타낼 수 있습니다.
이를 위 case에 적용하면,
SSE는 자유도가 n-2인 카이제곱분포를 따르는 확률변수고,
SSR은 자유도가 1인 카이제곱분포를 따르는 확률변수라고 할 수 있겠으며,
SSE와 SSR은 서로 독립(independent)이므로
이를 이용해 도출된 F-ratio는 자유도가 (1, n-2)인 F-분포를 따르게 됩니다!

자 그래서 우리는 이 F-ratio로 무엇을 할 것이냐.
바로 아래 문제에 대한 가설 검정, 즉 모형 적합도 평가를 할 겁니다.
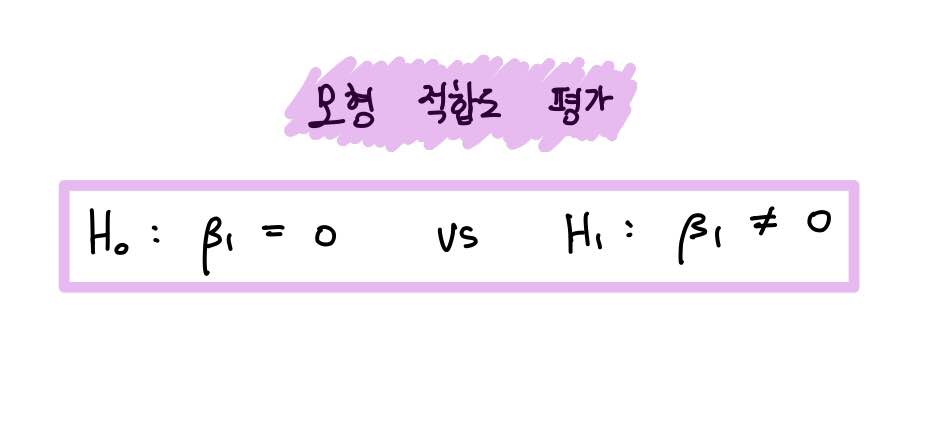
쉽게 말하면 우리가 세운 회귀모형 자체가 성립하냐를 물어보는 건데요.
회귀모형의 핵심은 설명변수 x와 반응변수 y 간의 관계를 찾아내는 것입니다.
즉 x가 y에 어떠한 영향을 주는지 파악하는 게 핵심이에요.
그리고 이러한 영향은 설명변수 x에 대응하는 회귀계수 β 로 나타낼 수 있습니다.
이 회귀계수 β 는 모형의 기울기(slope)를 의미하죠!
근데 만약 기울기가 0이라면?
설명변수와 반응변수 간의 아무런 (선형) 관계가 없단 얘기예요.
즉 우리가 세운 회귀모형은 그 순간부터 쓸모가 없어집니다. (해석적인 측면이 아닌 이론적인 측면에서의 쓸모없음)
뭐 x와 y가 아무런 선형 상관관계가 없다는 얘기니까 실제 연구에서 해석하고자 할 땐 이러한 결과가 쓸모가 있을 수도 있죠.
어떤 변수 간 아무런 관계가 없다는 것도 하나의 발견이자 연구 결과가 될 수 있잖아요?
그러므로 모형이 쓸모가 없다는 것은 통계학적인 측면에서 쓸모없다는 얘기입니다.
아무튼 그래서 단순회귀모형에서의 F-test는 기울기 계수 β1이 0인지 아닌지를 따져보게 되는 겁니다.
왜냐하면 모형에서 기울기 계수가 β1 하나만 있으니깐요!
만약 설명변수가 k개(k는 1보다 큰 정수) 있는 다중회귀모형이라면
귀무가설 H0 : 모든 k개의 회귀계수 βj (j = 1, 2, ..., k)는 0이다.
대립가설 H1 : not H0 (0이 아닌 회귀계수가 최소 1개 이상 존재한다.)
가 됩니다.
이 부분은 다음에 다시 다뤄드릴게요.
정리하면 이번 포스팅의 핵심은 이 세 가지 사실들을 바탕으로

다음과 같이 F(1, n-2)분포를 따르는 F-통계량을 유도할 수 있다는 것입니다.
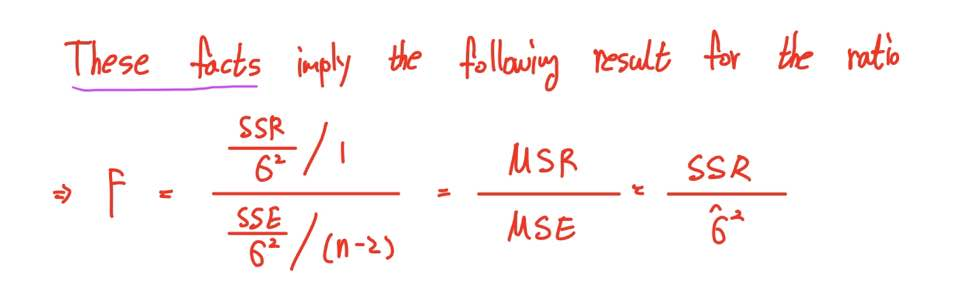
생각보다 길어져서 부득이하게 세 편으로 ANOVA&회귀분석 시리즈를 나눕니다.
다음 포스팅은 이 F-통계량을 이용해 가설 검정을 하는 것을 다뤄보겠습니다.
감사합니다.
잘 읽으셨다면 게시글 하단에 ♡(좋아요) 눌러주시면 감사하겠습니다 :)
(구독이면 더욱 좋습니다 ^_^)
- 간토끼(DataLabbit)
- University of Seoul
- Economics, Big Data Analytics
'Statistics > Regression Analysis' 카테고리의 다른 글
| [회귀분석] 결정계수(R²; Coefficient of Determination) (6) | 2020.10.06 |
|---|---|
| [회귀분석] ANOVA(분산분석)를 이용한 회귀분석 접근 (3) - ANOVA Table 해석 (6) | 2020.10.03 |
| [회귀분석] ANOVA(분산분석)를 이용한 회귀분석 접근 (1) - 제곱합(Sum of Squares) (9) | 2020.09.27 |
| [회귀분석] OLS추정량의 특성 (0) | 2020.09.22 |
| [회귀분석] 최소제곱법(Least Square Method)을 이용해 최소제곱추정량(LSE) 유도 (31) | 2020.09.18 |