
Review
참고 포스팅 :
2020/05/20 - [Statistics/Basic Statistics] - [기초통계학] 확률(Probability) 1 - 확률의 기본 개념
[기초통계학] 확률(Probability) 1 - 확률의 기본 개념
Review 참고 포스팅 : 2020/05/18 - [Statistics/Basic Statistics] - [기초통계학] 확률변수와 기댓값, 분산 [기초통계학] 확률변수와 기댓값, 분산 Review 참고 포스팅 : 2020/05/15 - [Statistics/Basic Statis..
datalabbit.tistory.com
2020/05/21 - [Statistics/Basic Statistics] - [기초통계학] 확률(Probability) 2 - 결합확률, 주변확률, 조건부확률
[기초통계학] 확률(Probability) 2 - 결합확률, 주변확률, 조건부확률
Review 참고 포스팅 : 2020/05/20 - [Statistics/Basic Statistics] - [기초통계학] 확률(Probability) 1 - 확률의 기본 개념 [기초통계학] 확률(Probability) 1 - 확률의 기본 개념 Review 참고 포스팅 : 2020/05..
datalabbit.tistory.com
안녕하십니까, 간토끼입니다.
지난 포스팅에서는 확률(Probability)을 주제로 몇 가지 기초적인 이론에 대해서 다뤘습니다.
이번 포스팅은 요 확률 시리즈의 마지막인 베이즈 정리(Bayes' Theorem)에 대해서 다뤄보겠습니다.
내용이 이해가 안 된다면 위 링크를 통해 읽고와주시기 바랍니다.

1. 베이즈 정리(Bayes' Theorem)
첫 번째 포스팅에서는 확률이 무엇인지 정의하면서, 크게 3가지 측면으로 구분하였습니다.
그중 공리적 확률을 중심으로 두 번째 포스팅에서는 이를 확장하여 결합확률, 주변확률, 조건부확률에 대해서 정의하고, 이 세 확률의 관계를 마지막 부분에 수리적으로 도식화하였습니다.
이번에 다루고자 하는 베이즈 정리도 이 세 확률의 관계를 좀 더 연관지어서 유의미한 관계를 도출해내고자 하는 목적을 갖고 있습니다.
일반적으로 어떤 사건 A와 다른 어떤 사건 B에 대한 조건부 확률 P(A|B), 그리고 B와 어떤 사건 A에 대한 조건부 확률 P(B|A)는 다를 것입니다.
조건부 확률의 정의를 생각해보면 P(B|A)란 사건 A가 발생하였을 때, 사건 B가 발생할 확률이죠.
즉, 선후관계를 따져보면 A가 먼저 발생하고, 이후 B가 발생할 확률이므로 우리는 이를 통해 인과관계를 추론할 수 있습니다.
A -> B 라고도 할 수 있겠네요. 이때 A는 독립변수, B는 종속변수라고 해도 논리상 큰 무리는 없어 보입니다.
그러나 A->B 와 B->A가 같다는 것은 아예 다른 문제입니다.
인과관계가 아예 바뀌는 것이므로, 위 명제가 참일 수는 있으나 일반적으로는 참이 아니겠죠?
이때 베이즈 정리는 우리가 알고 있는 정보 A->B를 바탕으로 B->A의 관계의 정도를 추론할 수 있게 해주는 테크닉입니다.
즉 우리가 사전에 A에 대한 정보를 바탕으로 P(A)와 P(B|A)를 알고 있다면, 이를 활용해 P(A|B)를 추론할 수 있게 해주는 것, 이것을 베이즈 정리라고 합니다.
다시 말해서 베이즈 정리는 새로운 증거 P(B)에 기반하여 과거의 정보를 향상시키거나 개선해줄 수 있는 이론이라는 거죠.

우리는 사건 A에 대한 정보를 알고 있다고 가정합시다.
저번 포스팅에서 조건부 확률을 정의했을 때 표본공간을 A의 근원사건 k개로 이루어진 표본공간으로 정의한다고 했으므로, 이 기억을 되살려 표본공간을 위 벤다이어그램처럼 A라고 가정합시다.
또한 A를 이루고 있는 4개의 작은 사건을 각각 A1, ..., A4라고 하고, 이 네 사건은 상호 배반이라고 가정합시다.
그렇다면 P(A) = P(A1) + P(A2) + P(A3) + P(A4) 라고 할 수 있으며, 이때 P(A)를 사전확률(Prior Probability)라고 합니다.
저번 포스팅을 기초로 하면 A에 대한 주변확률(Marginal Probability)라고도 할 수 있겠네요.
그럼 P(A|B)를 구하고 싶다면 어떻게 해야 할까요?
조건부확률의 정의에 의해 P(A|B) = P(A∩B)/P(B) 라고 표현할 수 있습니다.
앗, 근데 P(B)는 우리가 알지 못하는 새로운 정보네요? 현재로서는 구하기 어려워 보입니다.
자 그럼 다시 돌아가서 우리가 알고 있는 정보 P(B|A) 를 다시 한번 생각해봅시다.
P(B|A) 는 사건 A가 발생했을 때 사건 B가 발생할 확률을 의미합니다. 이때 P(B|A)를 우리는 우도(Likelihood)라고 합니다.
즉, 우도는 어떤 시행의 결과(Evidence) E가 주어졌을 때, 주어진 가설 H가 참이라면 결과 E가 나올 가능성은 얼마나 되겠냐는 의미인데... 좀 어렵습니다.
대충 이정도의 감만 잡고 넘어가셔도 괜찮고 추후 수리통계학을 다룰 일이 있다면 그때 심도 있게 다뤄보겠습니다.
어쨌든 우리는 조건부확률을 우도라고도 표현하며, 이를 통해 P(B|A), P(B|Ai) 를 각각 표현할 수 있습니다.
P(B|A)는 A라는 사건 집합의 우도이고, P(B|Ai)는 A의 근원사건 Ai에 대한 우도가 되겠네요.
다시 돌아가서 P(B)를 생각해보면, B라는 집합은 A라는 집합의 부분집합이라고 이해할 수 있습니다.
즉 P(B) = P(A∩B) 가 성립한다는 것이고, 이는 다시 생각해보면 A는 각 근원사건 Ai로 이루어져 있으므로,
P(B) = P(A∩B) = P(A1∩B) + P(A2∩B) + P(A3∩B) + P(A4∩B) 라고 할 수 있겠네요.
위 그림의 벤다이어그램을 참고하면 이해가 더욱 쉬울 것입니다.
자 이를 다시 정리하면 다음과 같이 나타낼 수 있습니다.

우리가 정의한 조건부확률(우도)를 약간 변형하여 나타냈으며, 이때 P(B)를 주변 우도(Marginal Likelihood)라고 합니다.
즉 새로운 정보 P(B)는 P(A∩B)와 같다고 할 수 있으며, 이 P(A∩B)는 A의 각 근원사건과 B의 교집합의 합으로 표현할 수 있고, 이 교집합은 다시 조건부확률에 의해 표현할 수 있습니다.
이를 다시 정리하면 다음과 같이 P(Ai | B) 를 구할 수 있으며, P(Ai | B)를 사후확률(Posterior Probability)이라고 합니다.
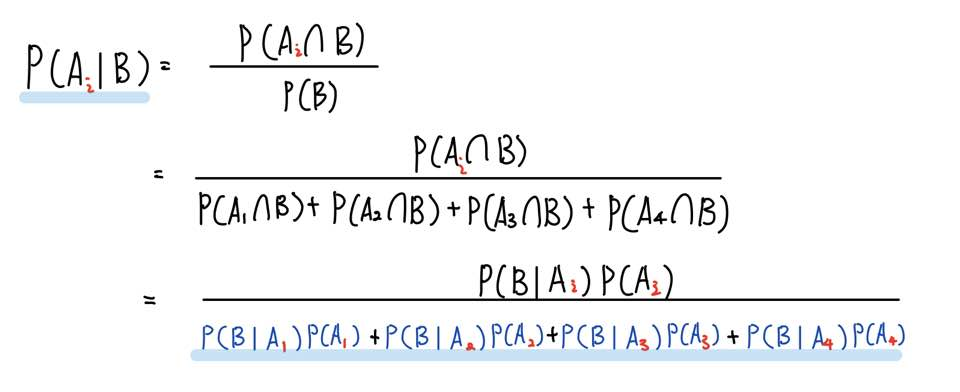
위 베이즈 정리는 추후 통계학을 공부할 때, 혹은 머신러닝 이론을 적용할 때 굉장히 유용하게 쓰입니다.
특히 머신러닝 이론 중 나이브-베이즈 분류(Naive-Bayes Classification)에서 핵심적으로 쓰이므로, 잘 알아두시기 바랍니다.
어차피 이 블로그의 목적은 머신러닝을 다루기 위함이므로, 앞에서 다루는 통계 기초는 ML을 위한 빌드업입니다.
그때 다룰 일이 있으면 리마인드해드리겠습니다.
확률에 대한 이론은 이정도로 마치고, 추후 수리통계학을 배울 때 보다 엄밀하게 다뤄보도록 하겠습니다.
다음 포스팅은 확률분포에 대해서 다룰 예정인데, 그전에 확률을 추정하는 방법론인 마르코프 부등식과 체비셰프 부등식을 짚고 넘어가겠습니다.
감사합니다.
잘 읽으셨다면 게시글 하단에 ♡(좋아요) 눌러주시면 감사하겠습니다 :)
(구독이면 더욱 좋습니다 ^_^)
- 간토끼(DataLabbit)
- University of Seoul
- Economics, Big Data Analytics
'Statistics > Basic Statistics' 카테고리의 다른 글
| [기초통계학] 체비셰프 부등식(Chebyshev Inequality) (3) | 2020.06.24 |
|---|---|
| [기초통계학] 마르코프 부등식(Markov Inequality) (2) | 2020.05.26 |
| [기초통계학] 확률(Probability) 2 - 결합확률, 주변확률, 조건부확률 (6) | 2020.05.21 |
| [기초통계학] 확률(Probability) 1 - 확률의 기본 개념 (0) | 2020.05.20 |
| [기초통계학] 공분산과 상관계수 (12) | 2020.05.19 |