
[회귀분석] 단순선형회귀분석(Simple Linear Regression) 개념
Review
참고 포스팅 :
2020/09/15 - [Statistics/Regression Analysis] - [회귀분석] 회귀분석 모델의 소개
안녕하십니까, 간토끼입니다.
지난 포스팅에서는 회귀분석이 무엇인지에 대해서 간단히 다뤄보았습니다.
이번 포스팅에서는 회귀모형에서 설명변수가 1개인 모델, 즉 단순선형회귀분석(Simple Linear Regression)에 대해서 다뤄보겠습니다.
한번에 전부 다루기엔 양이 많아서 여러 번 나누어 포스팅할 계획입니다.

단순선형회귀모형은 모형 내 설명변수가 1개만 있는 모형을 말합니다.
즉 1개의 설명변수만으로 반응변수 Y에 대한 영향을 파악하기 위해 사용합니다.
예를 들어 한 노동자의 임금(Wage)를 예측하기 위해 노동자의 교육 수준(Edu)을 설명변수로 활용한다고 가정해보죠.
직관적으로 판단했을 때도, 교육 수준이 높을수록 노동자의 임금 수준이 올라갈 것 같다는 생각이 듭니다.
다만 임금이 교육 수준만으로 결정될까요?
그 사람의 이전 경력(인턴, 이전 직장, 대외활동 등)도 임금에 유의미한 영향을 줄 수 있고, 그 사람의 나이(Age), 신체 조건 등 임금에 영향을 줄 수 있는 요소는 교육 수준을 제외하고도 매우 많습니다.
이러한 경우, 교육 수준이 임금을 '어느정도는' 예측할 수 있지만, 아무래도 완전히 예측하기는 어려워 보입니다.
이러한 이유에서 단순회귀분석이 실제 분석에서 잘 쓰이지는 않습니다.
현실의 복잡한 문제를 설명변수 1개만으로 파악하기는 사실 어렵기 때문이죠.
다만 설명변수가 모형에 1개씩 추가될수록 모형이 점점 복잡해지기 때문에,
단순회귀모형에서 쓰이는 개념을 우선적으로 잘 파악한다면, 다중회귀분석에서도 큰 틀에서는 일맥상통하므로 이해하기 더욱 쉬우실 것입니다.
이러한 맥락에서 단순회귀모형을 공부하면 좋을 것 같습니다.
각설하고 모형을 좀 더 살펴보죠.
단순회귀모형은 다음과 같이 표현됩니다.
특히 오차항을 제외한 부분을 μ (조건부기댓값)으로 표현할 수 있습니다.
이를 이해하기 위해 단순회귀분석의 몇 가지 중요한 고전적인 가정을 짚고 넘어가보죠.
1. 설명변수 X는 확률변수가 아니라 비확률변수(주어진 것)으로 간주한다.
- 우리가 일반적으로 X는 항상 변수로써 사용을 해서 개념이 헷갈릴 수 있으나, 회귀분석에서는 X를 주어진 것으로 가정하고 문제에 접근합니다.
만약 X를 변수로 간주한다면, 모형 내 확률변수가 무척이나 많아서, 문제를 풀기 다소 복잡해집니다.
그러한 의미에서 X를 비확률변수(확률변수가 아니다!)라고 간주하며, 의미가 조금 어려우시다면 쉽게 상수로 가정한다고 생각하면 이해하기 쉬우실 것입니다. 주어진 것이라는 의미는 상수라고 이해하는 것과 비슷하니깐요.
2. 오차항의 기댓값은 0이다. 그러므로 Y의 조건부기댓값은 오차항을 제외한 부분과 같다.
- 여기서 Error Term ε은 확률변수(Random Variable)입니다. 이후 보일 예정이지만 오차의 총합은 0입니다.
기댓값도 당연히 0이고요. 그렇기에 Y의 조건부기댓값 μ 이 오차항의 기댓값이 0으로 되어버림으로써 위와 같이 됩니다.
조건부기댓값이라고 표현한 것은 X를 주어진 것으로 간주하기 때문입니다.
3. 오차항의 분산은 σ^2이다.
- 오차항의 분산이 σ^2이라는 말의 의미는, 분산이 변수가 아닌 상수로 고정되어 있다는 것입니다.
분산은 확률변수가 평균을 기준으로 퍼져있는 정도를 말하죠?
분산이 임의의 상수로 고정되어 있으므로, 설명변수 X에 대응하는 반응변수 Y의 값이 퍼져있는 정도가 전 구간에서 균일하며, 이를 등분산성(homoskedasticity)이라고 합니다.
만약 분산이 구간에 따라 변한다면 이를 이분산성(Heteroskedasticity)라고 합니다.
4. 서로 다른 오차 εi, εj에 대하여, 공분산 Cov(ei, ej) = 0 이다.
- 서로 다른 오차 간엔 어떠한 상관관계도 존재하지 않는다는 것으로, 오차의 독립성 가정이라고도 합니다.
즉 오차 ε는 Random Variable이므로 오차의 발생이 다른 오차에 영향을 받지 않아야 합니다.
만약 어떠한 값에 의해 오차가 영향을 받아 값이 결정된다면,
이러한 영향을 잡아내지 못할 경우 모형이 불안정하여 예측값이 부정확하게 되겠죠.
오차 간 상관관계가 있는 경우를 자기상관(Autocorrelation)이 있다고 합니다.
예를 들어 시계열 자료(Time Series Data)에서 현재 시점의 자료의 값은 과거 시점의 값에 영향을 받습니다.
어떤 상품의 가격의 추세를 살펴보면,
2008년엔 1000원, 2009년엔 1100원, 2010년엔 1150원 ... 이라고 했을 때 2011년에 갑자기 5000원이 되거나 100원이 되진 않겠죠?
위와 같은 경우에서는 이러한 자기상관의 패턴을 잡아줘야 예측력을 높일 수 있습니다만,
우선 회귀분석에서는 오차항이 random이라고 가정합니다.
위 가정들을 크게 오차의 정규성, 독립성, 등분산성 가정이라고 합니다.
위 가정들은 선형회귀모형이 성립하는 중요한 가정이지만,
어떻게 보면 현실과 다소 괴리가 있을 수 있는 경직적이자 이상적인 가정이라 위 가정이 깨지는 경우가 많습니다.
이후 위 가정들이 하나씩 깨졌을 때 어떠한 방법으로 대처해야 할지에 대해서도 살펴볼 예정이고요.
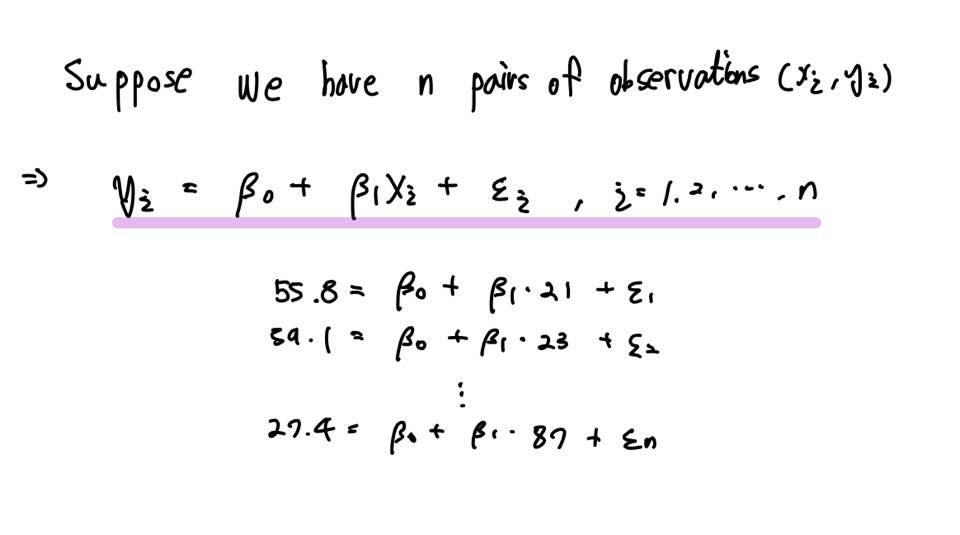
위는 n개의 Sample이 있을 때 위와 같이 표기할 수 있음을 의미합니다.
결국 모든 통계 모형이 그러한 것과 같이, 회귀분석도 sample로부터 population을 추론하는데요.
모집단에서의 Parameter(모수)가 β0, β1라면, 모집단의 Sample로부터 추정하여 β0, β1의 Estimator를 구해야 합니다.
왜냐하면 β0, β1는 결국 설명변수 X가 Y에 얼마만큼의 영향을 끼치는지 알려주는 중요한 지표가 되기 때문이죠.

이는 최소제곱법(Least Square Method)을 이용해 β0, β1의 Estimator를 구할 수 있습니다.
최소제곱법을 이용해 구하는 과정은 다소 포스팅이 길어질 것 같아 다음 포스팅에서 이어서 다뤄보겠습니다.
감사합니다.
잘 읽으셨다면 게시글 하단에 ♡(좋아요) 눌러주시면 감사하겠습니다 :)
(구독이면 더욱 좋습니다 ^_^)
- 간토끼(DataLabbit)
- University of Seoul
- Economics, Big Data Analytics