[회귀분석] 최소제곱법(Least Square Method)을 이용해 최소제곱추정량(LSE) 유도
Review
참고 포스팅 :
2020/09/17 - [Statistics/Regression Analysis] - [회귀분석] 단순선형회귀분석(Simple Linear Regression) 개념
안녕하십니까, 간토끼입니다.
지난 포스팅에서는 단순회귀분석의 개념에 대해서 다뤄보았습니다.
특히 지난 포스팅의 마지막에 최소제곱법(Least Square Method)을 이용해 β0, β1의 Estimator를 구할 수 있다고 말씀을 드렸는데요.
이번 포스팅에서는 최소제곱법(Least Square Method)을 이용해 β0, β1의 Estimator를 구하는 방법에 대해서 다뤄보겠습니다.

모든 통계 모형이 그러한 것과 같이, 회귀분석도 sample로부터 population을 추론합니다.
즉, 모집단에서의 Parameter(모수)가 β0, β1라면, 모집단의 Sample로부터 추정하여 β0, β1의 Estimator를 구해야 한다는 것이죠.
이렇게 구한 β0, β1의 추정량은 설명변수 X가 Y에 얼마만큼의 영향을 끼치는지 알려주는 중요한 지표가 됩니다.
이를 위해 오차의 제곱합을 최소화하는 최소제곱추정을 하게 됩니다.
왜 오차의 제곱합을 최소화할까요?

다음과 같이 5개의 데이터 [1, 2, 4, 7, 9]가 있다고 가정하겠습니다.
위 데이터의 평균은 4.6이고, 편차 = 데이터 - 평균 공식을 이용해 편차를 위와 같이 구한 후,
편차의 합을 구해보았습니다.
보시다시피 0이 나오죠?
가장 좋은 건 오차를 최소화하는 최적의 추정량을 구하는 것이겠죠.
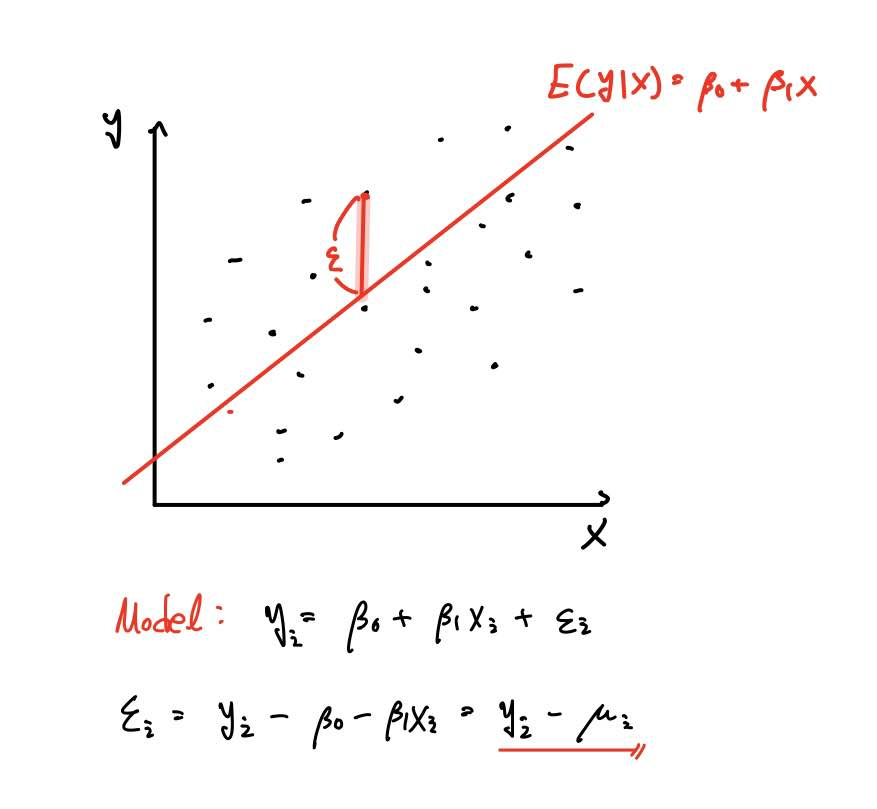
왜냐하면 오차를 줄일수록 반응변수 Y를 최대한 잘 예측할 수 있으니깐요.
그러한 의미에서 오차를 가장 작게 만드는 Parameter 추정량이 최적의 Parameter 추정량이라는 것과 같은 의미입니다.
다만 오차의 총합은 항상 0이 되니, 오차를 제곱한 값을 총합한 것을 목적함수로 세우고 이를 최소화하는 최적의 parameter를 찾아나가는 것입니다.

다시 표현하자면 우리가 해결하고자 하는 문제는 위와 같습니다.
위 목적 함수는 일종의 Cost function(비용 함수)라고도 볼 수 있습니다.
함수를 최소화하지 못하면 오차가 커지니까, 우리가 예측하고자 하는 Y_hat이 부정확하게 되는 거죠.
우리가 세운 모델의 예측력이 떨어지면 그에 따른 비용(cost)이 커지게 되겠죠?
그러한 의미에서 위 목적함수(Cost function)을 최소화하는 해 b0*, b1*을 찾아야 하는데요.
고등학교 수학에서 함수를 1계 미분하여 기울기가 0이 되는 지점을 찾으면 극솟값, 혹은 극댓값이라고 배웠죠?
여기선 함수의 형태가 아래로 볼록한 convex function이니, 1계 미분한 값이 0을 만족한다면 당연히 극솟값이겠죠.
(정석대로라면 2계 미분한 값(*다변수함수라면 Hessian Matrix)이 0보다 큰지, 작은지 등도 따져봐야겠죠.)
따라서 목적함수를 미분한 값이 0이 되도록 하는 값 b0*, b1*를 찾아주면 됩니다.

위 다변수함수를 그래프로 그리면 위와 같습니다.
위 그래프에서 보는 것과 같이, 위 함수의 기울기가 0이 되는 지점을 찾으면 오차제곱합을 최소화할 수 있겠죠?
따라서 이 다변수함수를 목적함수로 세우고, 최소화하는 과정을 통해 β0, β1의 Estimator를 구해보겠습니다.

우리가 구하고자 하는 것은 β0, β1의 Estimator이므로, 이 두 parameter에 대해 오차제곱합을 표현할 수 있습니다.
이를 각 β0, β1에 대해 편미분을 해주면 식을 2개 얻을 수 있는데요.
이를 정규 방정식(Normal Equation)이라고 합니다.
이제 최적화의 1계조건에 의해 편미분한 값이 0이 되는 식 두 개를 얻었으니,
위 식을 연립하여 β0, β1의 식을 유도할 수 있습니다.

식을 풀면 우측과 같이 됨을 알 수 있습니다.
이때 계산의 용이함을 위해 간단한 연산을 해줍니다.
연립방정식에서 미지수 하나를 구하기 위해 다른 미지수를 소거해주잖아요?
그러한 맥락에서 β0가 있는 항을 소거하기 위해 (a)식에는 sigma_xi를, (b)식에는 n을 곱해줍니다.

연립방정식을 전개하면 위와 같은 식을 얻을 수 있습니다.
어차피 우변의 값은 0이므로, 좌변은 β1 만 남겨두고 나머지 항은 우변으로 넘겨줍니다.

회귀분석이든 기초통계학이든 약간의 변환 작업에 대해 익숙해져야 합니다.
제가 옆에 표기한 주석을 참고하시면 각각의 식에서의 항이 어떻게 바뀌는지 직접 써보면 쉽게 이해하실 수 있을 겁니다.

하나만 언급하자면, x의 평균은 스칼라(상수)로 표현되죠? 확률변수가 아닙니다.
x의 평균이 상수니까 당연히 x 평균의 제곱도 상수겠죠.
그러므로 sigma의 성질에 따라 상수에 sigma를 취해준 값은 결국 상수에 n을 곱하는 것과 같습니다.
만약 위 유도 과정이 이해가 안 되시면 댓글 남겨주세요.
답변 드리겠습니다.

β1 의 최소제곱추정량 유도 과정을 한 페이지에 정리하면 다음과 같습니다.
β1 에 비해 β0 은 유도과정이 어렵지 않습니다.

위 유도 과정 중 정규 방정식 (a) 를 가져와서 이를 이용해 보이면 됩니다.
쉽죠?
정리하면 이러한 방식을 최소제곱법(Least Square Method)라고 하며, 최소제곱법을 통해 얻어낸 추정량을 최소제곱추정량(Least Square Estimator ; LSE)라고 합니다.
그리고 최소제곱법을 이용해 Population의 Parameter를 추정하여 회귀분석을 하는 것을 OLS(Ordinary Least Square) 회귀분석이라고 합니다.
다른 말로 하면 최소제곱법을 이용해 구한 추정량을 OLS 추정량이라고도 합니다.
용어는 비슷비슷하게 섞여서 쓰이니까 알아두시면 좋습니다.
다음 포스팅에서는 단순회귀분석을 좀 더 다뤄보도록 하겠습니다.
감사합니다.
잘 읽으셨다면 게시글 하단에 ♡(좋아요) 눌러주시면 감사하겠습니다 :)
(구독이면 더욱 좋습니다 ^_^)
- 간토끼(DataLabbit)
- University of Seoul
- Economics, Big Data Analytics