
[프로그래머스] 성격 유형 검사하기 Python 풀이
# 해당 포스팅은 이제 막 알고리즘 공부를 시작한 초보 수준에서 작성했음을 이해해주시고, 비난보다는 따뜻한 조언을 부탁드립니다.
안녕하십니까, 간토끼입니다.
오늘은 프로그래머스(Programmers) 성격 유형 검사하기 문제에 대해 다뤄보겠습니다.
2022 카카오 인턴십 코딩테스트 문제(Lv.1 수준)입니다.

1. 문제 링크
https://school.programmers.co.kr/learn/courses/30/lessons/118666
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
MBTI같은 카카오 성격 유형 검사지를 만드는 문제입니다.
성격 유형 검사는 4개의 지표로 성격 유형을 구분하고, 각 지표는 두 유형 중 하나로 결정됩니다.
예를 들어 1번 지표는 라이언형(R), 튜브형(T) 중 하나로 결정되는 형식입니다. 만약 라이언형의 점수가 더 높다면 1번 지표의 성격 유형은 "R"이 됩니다.
각 성격 유형을 결정하는 요소는 검사지의 질문에 답한 점수가 됩니다.
만약 질문이 NA(네오형, 어피치형)을 묻는 질문이었다면, 매우 비동의(1번)으로 응답할 경우 네오형(N)에 3점이 추가되는 방식입니다.
반대로 질문에 약간 동의(5번)으로 응답할 경우, 어피치형(A)에 1점이 추가되는 방식입니다.
이런 식으로 주어진 질문에 대한 점수를 계산하여 검사자의 성격 유형을 도출하면 됩니다.
만약 특정 유형의 점수가 같다면 유형의 사전순으로 유형을 결정하게 됩니다.
예를 들어 네오형(N)과 어피치형(A)의 점수가 8점으로 같다면, A가 N보다 빠른 순으로 배치돼있으므로 어피치형(A)로 결정됩니다.
이런 식으로 구하면 되고, input은 survey(어떤 유형을 묻는지 질문)과 choices(질문에 대한 답변)으로 주어집니다.
2. 접근 방법
다음과 같이 접근하였습니다.
먼저 Dictionary를 활용해 성격유형 사전을 만들었습니다.
각 유형은 이니셜의 앞자로 표기되므로,
R, T, C, ..., N 까지 8개의 유형을 키(Key)로 하고, 각 유형의 점수(Score)를 값(value)으로 합니다.
물론 초기값은 0으로 해야겠죠.
이후 Survey의 길이에 따라 n번의 loop를 구성합니다.
먼저 Survey의 각 원소는 "RT" 이런 식으로 두 개의 성격유형이 붙은 형태로 이루어져있으므로,
임의로 앞의 유형은 q_1, 뒤의 유형은 q_2로 하겠습니다.
그리고 선택지에 대한 답변은 1부터 7까지의 수 중 하나가 되죠.
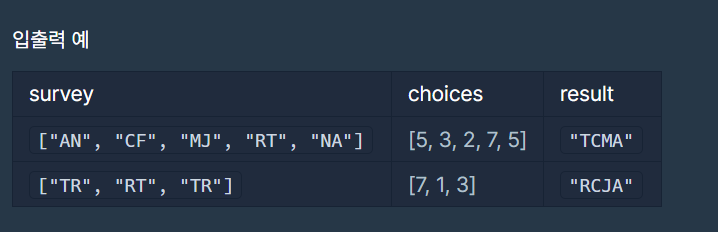
예를 들어 "AN"의 답변이 5이라면 앞 유형(q_1)은 A가 되고, 뒤 유형(q_2)은 N이 되죠.
그리고 성격유형 점수의 배점표 리스트를 [3,2,1,0,1,2,3] 와 같이 만들고,
주어진 답변(choices)이 5이므로, 위 배점표 리스트에서 인덱스가 4인(=5-1) 값을 찾아주면 됩니다.
인덱스가 3보다 크므로 뒤 유형의 기존 점수에 1점을 더해주면 되겠네요.
이런식으로 각 유형별로 점수를 구하고,
최종적으로 If문을 이용해 유형별 점수를 비교해서 성격 유형을 정해주면 되는 문제였습니다.
어렵진 않았습니다.
3. 코드
# 프로그래머스 lv.1
# 성격 유형 검사하기 (카카오 2022 인턴십)
# 지표(Survey) : 1번(RT), 2번(CF), 3번(JM), 4번(AN)
# survey : ["AN", "CF", "MJ", "RT", "NA"]
# choices : 1,2,3,4,5,6,7 (매우 비동의 ~ 매우 동의)
# Ex. "AN" : 1번(A 3점) ~ 7번(N 3점), "CF" : 1번(C 3점) ~ 7번(F 3점)
def solution(survey, choices):
# 1. 성격유형 사전 만들기
personality_dict = {'R': 0, 'T' : 0, 'C': 0, 'F' : 0, 'J': 0, 'M' : 0, 'A': 0, 'N' : 0}
# 2. Survey 및 choice 판단 loop
n = len(survey) # survey 길이
for i in range(n):
question = survey[i]
score = choices[i]
q_1 = question[0] # 앞 유형 ex. RT -> R
q_2 = question[1] # 뒷 유형 ex. RT -> T
list_q = [3,2,1,0,1,2,3] # 성격유형점수 배점표
idx = score - 1
if idx < 3:
personality_dict[q_1] += list_q[idx]
elif idx == 3:
continue # score == 0이면 패스
else:
personality_dict[q_2] += list_q[idx]
# 3. 각 유형별 점수 비교
answer = ''
if personality_dict['R'] >= personality_dict['T']:
answer = answer + 'R'
elif personality_dict['R'] < personality_dict['T']:
answer = answer + 'T'
if personality_dict['C'] >= personality_dict['F']:
answer = answer + 'C'
elif personality_dict['C'] < personality_dict['F']:
answer = answer + 'F'
if personality_dict['J'] >= personality_dict['M']:
answer = answer + 'J'
elif personality_dict['J'] < personality_dict['M']:
answer = answer + 'M'
if personality_dict['A'] >= personality_dict['N']:
answer = answer + 'A'
elif personality_dict['A'] < personality_dict['N']:
answer = answer + 'N'
return answer
감사합니다.
잘 읽으셨다면 게시글 하단에 ♡(좋아요) 눌러주시면 감사하겠습니다 :)
(구독이면 더욱 좋습니다 ^_^)
* 본 블로그는 학부생이 운영하는 블로그입니다.
따라서 포스팅에 학문적 오류가 있을 수 있으며, 이를 감안해서 봐주시면 감사하겠습니다.
- 간토끼(DataLabbit)
- B.A. in Economics, Data Science at University of Seoul